Share this post
AI chatbots can't do your taxes - here's what actually works
Last week, the New York Times published a piece titled "A Word to the Wise: Don't Trust A.I. to File Your Taxes." They tested ChatGPT, Gemini, Claude, and Grok on eight fictional tax scenarios. The chatbots miscalculated refunds by an average of more than $2,000.
I run an AI tax company and I completely agree with the headline. Here's why that's not a contradiction, and what it tells you about how purpose-built AI actually differs from general models.
The right conclusion to the wrong test
The NYT tested whether consumers can use general AI chatbots to file their own taxes. The conclusion: they can't. That's correct.
But the test was designed around a question nobody building AI for tax professionals is actually trying to answer. Nobody in this industry is trying to replace the tax professional with a chatbot. That would be like handing a medical student a textbook, leaving them alone with a patient, and then reporting that medical students aren't ready to practice medicine independently. The finding is technically true and completely beside the point. Medicine works because of systems, supervision, and layered review. Tax preparation works the same way.
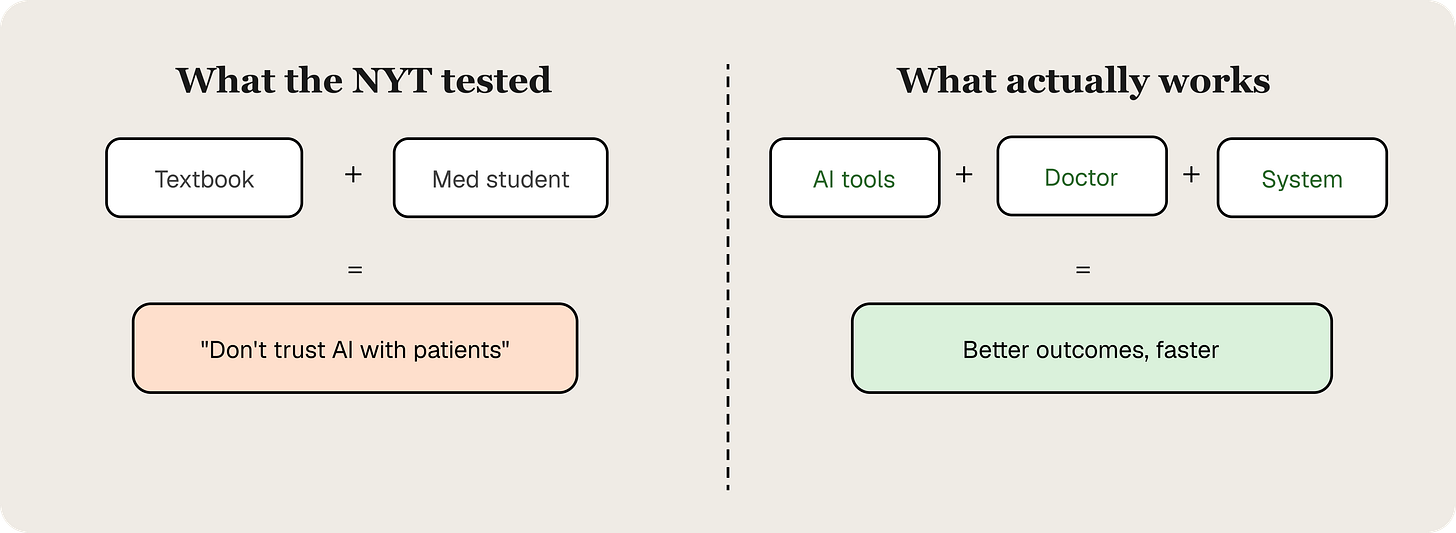
The real question isn't "can AI do your taxes?" It's "can AI make the people who do your taxes faster, more accurate, and more focused on the work that requires their judgment?" The answer to that is yes. And it requires a fundamentally different architecture than a general chatbot.
Why general AI fails at tax specifically
The expert commentary in the NYT piece is more useful than the test itself.
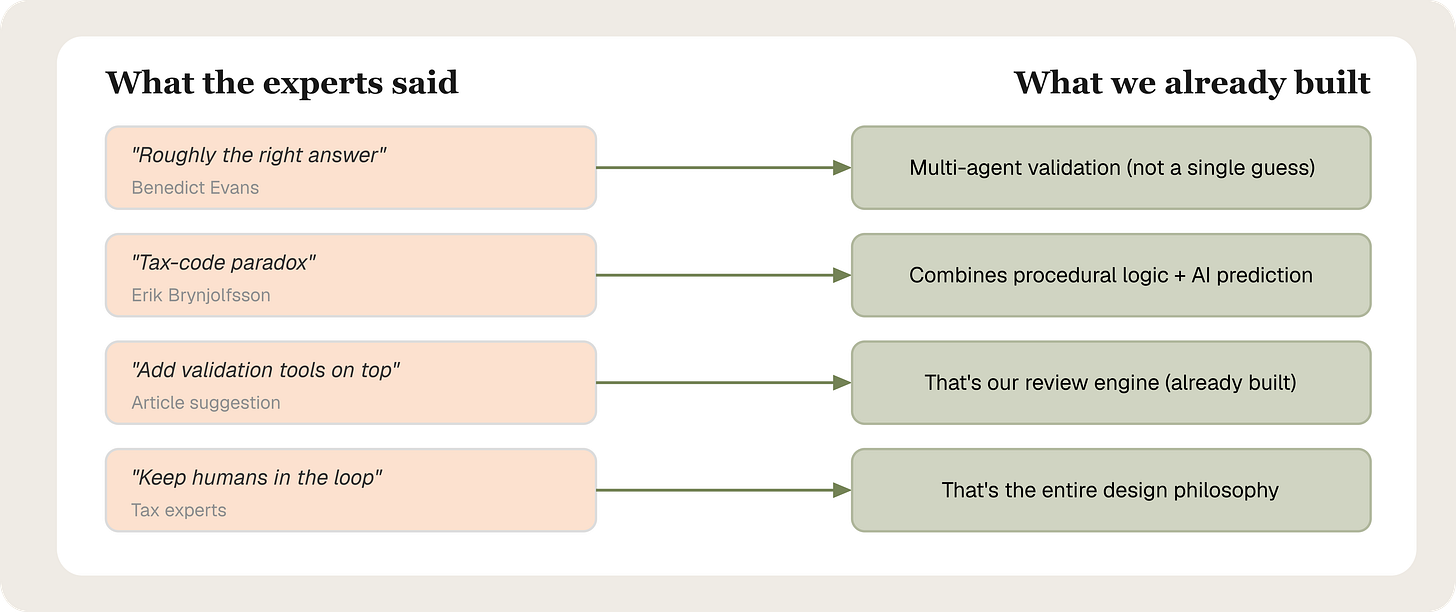
Benedict Evans told the Times that AI gives you "roughly the right answer, and that's not what you want." He's right. Roughly right is dangerous in tax because errors cascade. A wrong cost basis on an early form produces wrong numbers on downstream forms. By the time it reaches e-filing, the return looks plausible but is wrong throughout.
Erik Brynjolfsson from Stanford described the "tax-code paradox": traditional tax tools follow procedural if-then logic built for precision, while AI models are prediction engines optimised for plausible output, not correct output. He's describing a real limitation. The failure modes the chatbots produced in the NYT test are predictable from this: bracket calculations instead of the IRS-mandated Tax Table, structural errors on complex forms, cascading mistakes from one early wrong input.
These aren't random errors. They're what happens when you use a prediction engine to do a rules-enforcement job.
What purpose-built architecture actually does differently
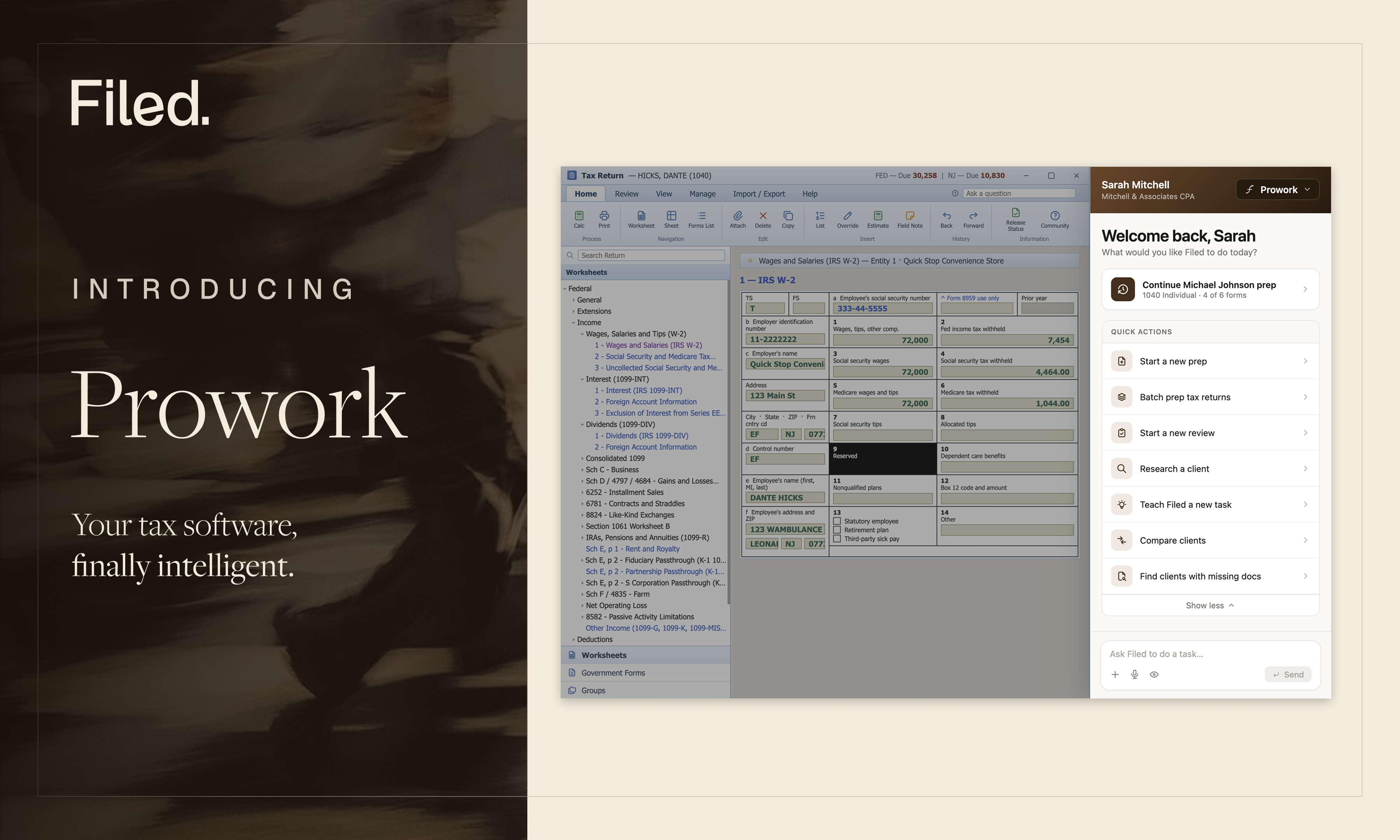
Filed uses multi-agent orchestration, where specialised AI components handle different parts of the tax preparation process and a deterministic validation layer runs independently of the AI output at every step. The system doesn't guess and hope. It produces output, then checks it against IRS rules separately. When they don't agree, it flags the discrepancy before it reaches a human reviewer.
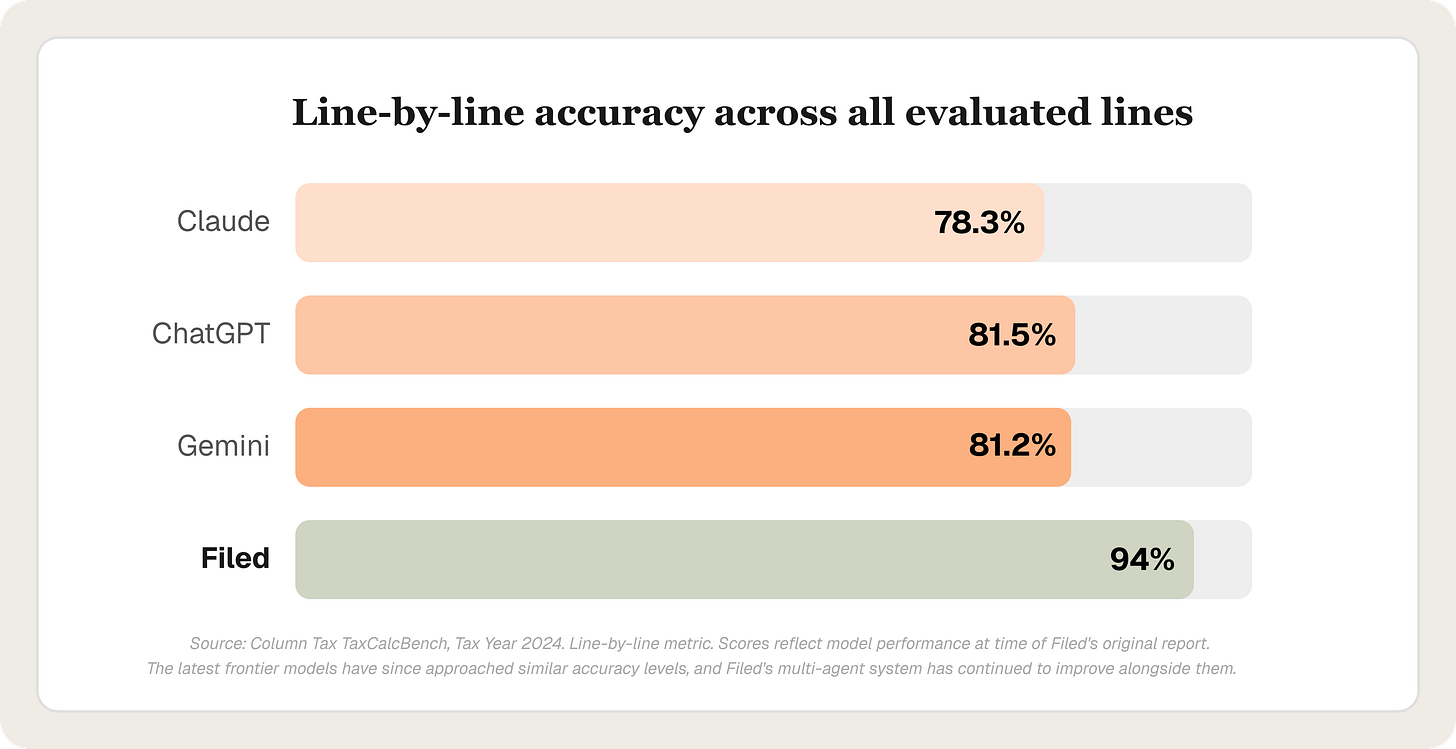
This isn't a theoretical design choice. Column Tax released TaxCalcBench earlier this year, the first open-source benchmark for AI tax accuracy. We ran Filed against it alongside ChatGPT, Claude, and Gemini.
The generic chatbots scored between 23% and 42% on complete returns. Filed scored 72.5%. On a line-by-line basis, which maps to how tax professionals actually review returns, Filed reached 94% accuracy.
Since then, frontier models have improved and the latest generation is approaching that 94% threshold on their own. That's worth noting. But Filed's multi-agent architecture is built on top of these same frontier models. When they improve, our accuracy improves too. The 94% we published months ago is a floor, not a ceiling.
The part the test doesn't cover at all
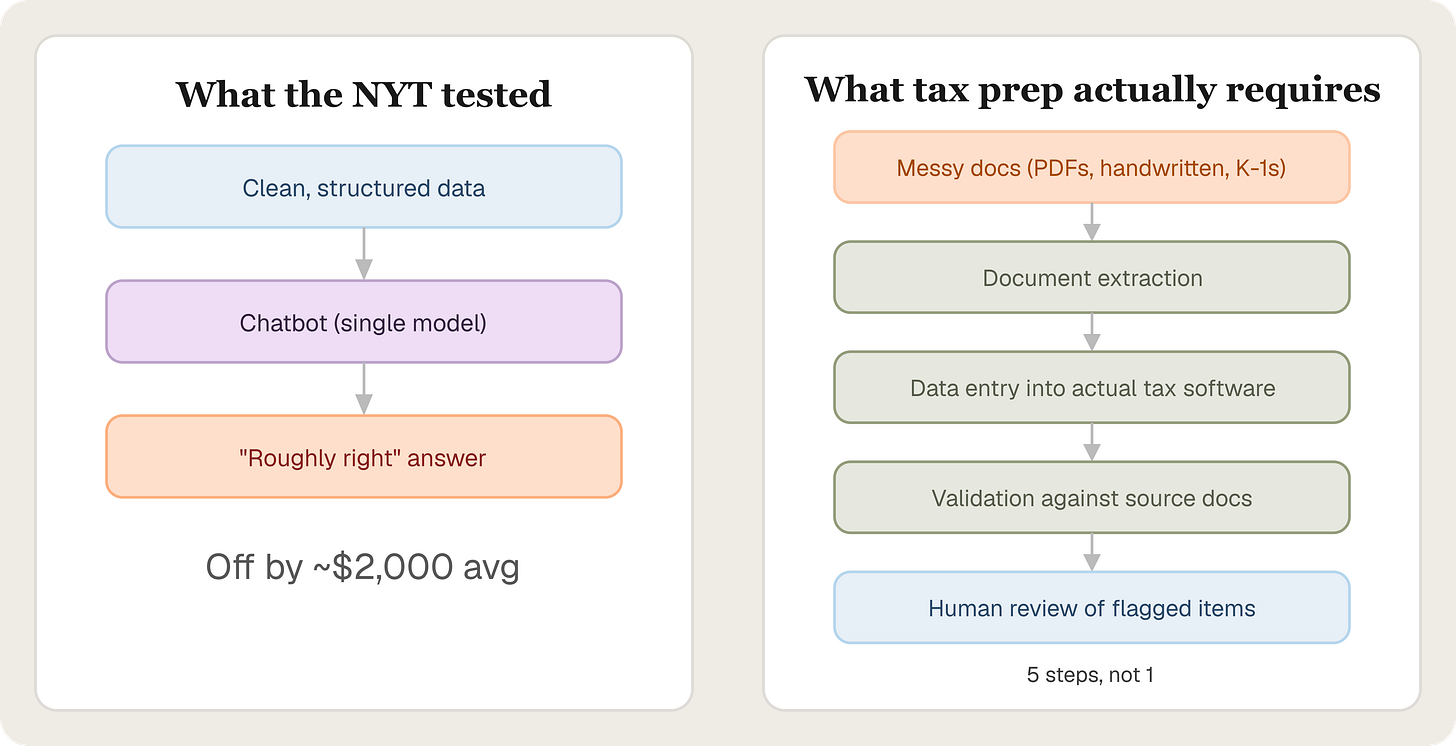
There's one thing the NYT piece doesn't address, and it's the most important: none of the chatbots they tested do tax preparation.
Calculating a return from structured data is one step. In practice, tax preparation starts with a pile of messy source documents. PDFs. Handwritten notes. Clients who send ten K-1s in five different formats. The work involves extracting information from those documents, entering it into professional tax automation platforms like Drake, ProConnect, UltraTax, or CCH Axcess, navigating rolled-over data from prior-year returns, adding depreciation schedules on top of existing ones, and validating everything against the original sources before anything gets filed.
No chatbot does any of that. The NYT handed models pre-structured data and asked them to compute. The gap between that test and actual tax preparation doesn't close just because general AI gets better at arithmetic.
What this means practically
Don't trust AI to file your taxes. Trust your tax professional. Then give them a tax automation platform purpose-built for the job, one with document-first architecture, deterministic validation, and humans in the loop for the decisions that actually require judgment.
That's not a hedge. It's the design philosophy that produces 94% line-by-line accuracy instead of 23%.
Subscribe to our newsletter
Explore our latest insights
Discover valuable articles to enhance your knowledge.