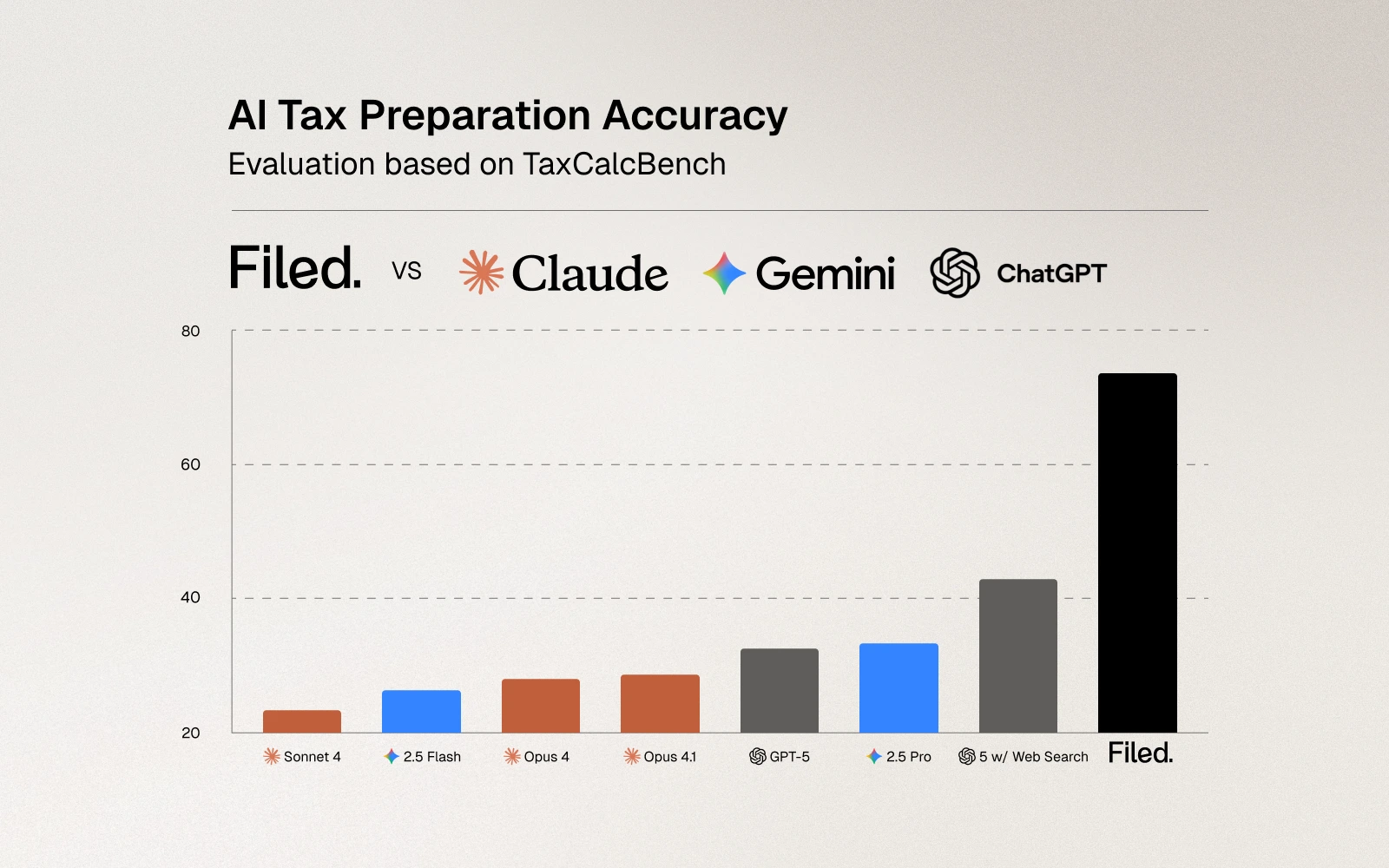
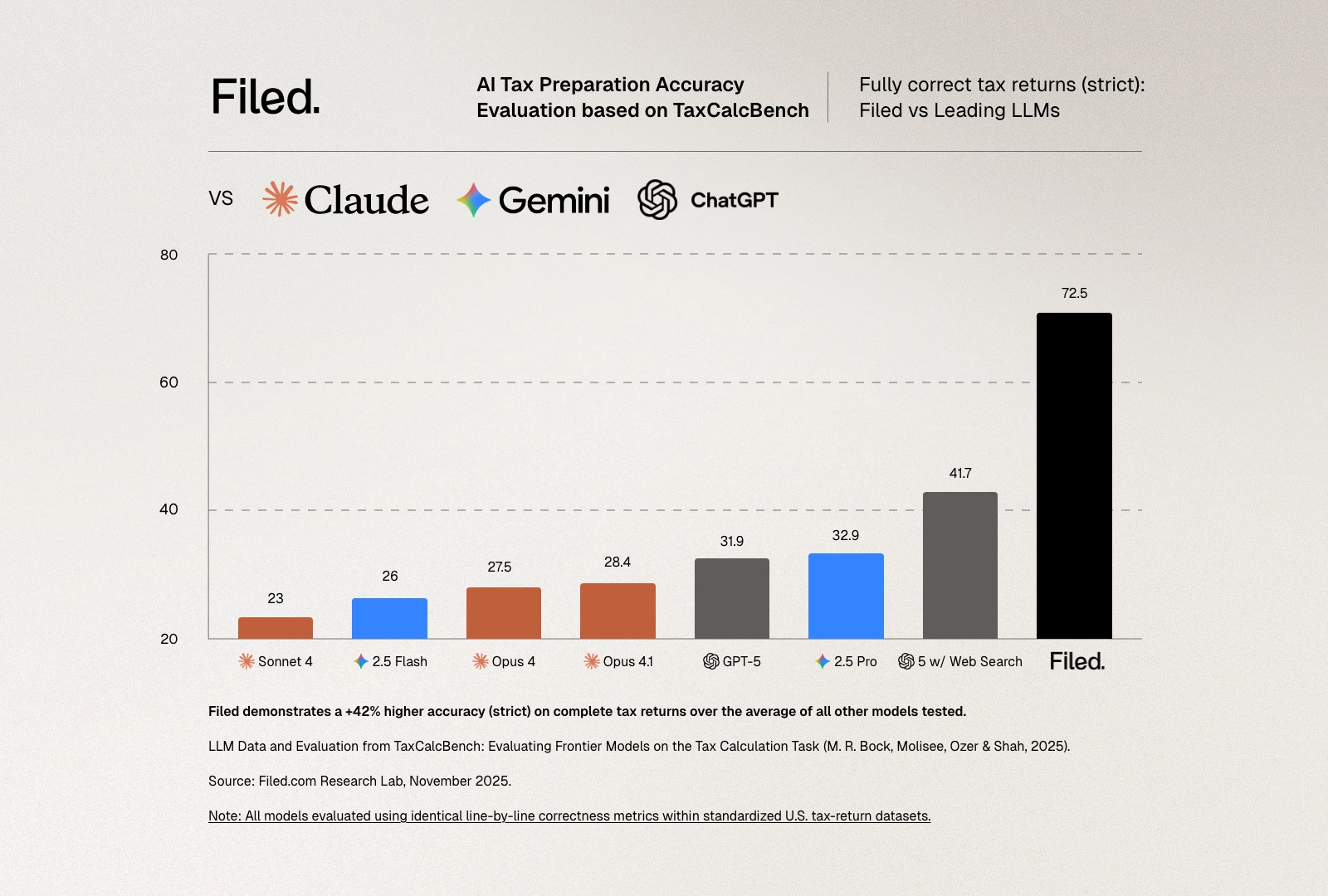
The question of whether AI can prepare taxes has moved from speculation to rigorous testing. Earlier this year, Column Tax released TaxCalcBench, an open-source benchmark designed to evaluate how well frontier AI models can calculate personal income tax returns. Their findings were sobering: even the best-performing large language model achieved only 32.35% accuracy on a diverse but controlled set of federal-only tax returns.
At Filed, we participated in the TaxCalcBench evaluation to understand where our system stands relative to these baseline measurements. Our results tell an important story, not just about performance metrics, but about what it actually takes to build AI systems that work in the complex reality of tax preparation.
Understanding TaxCalcBench's contribution
Column Tax deserves credit for creating the first rigorous, open-source benchmark for AI tax calculation. TaxCalcBench tests models on 51 Tax Year 2024 federal tax returns, covering various filing statuses, income sources, and common credits and deductions. The benchmark focuses specifically on the calculation phase of tax preparation: given complete, correctly formatted information, can an AI model compute the tax return accurately?
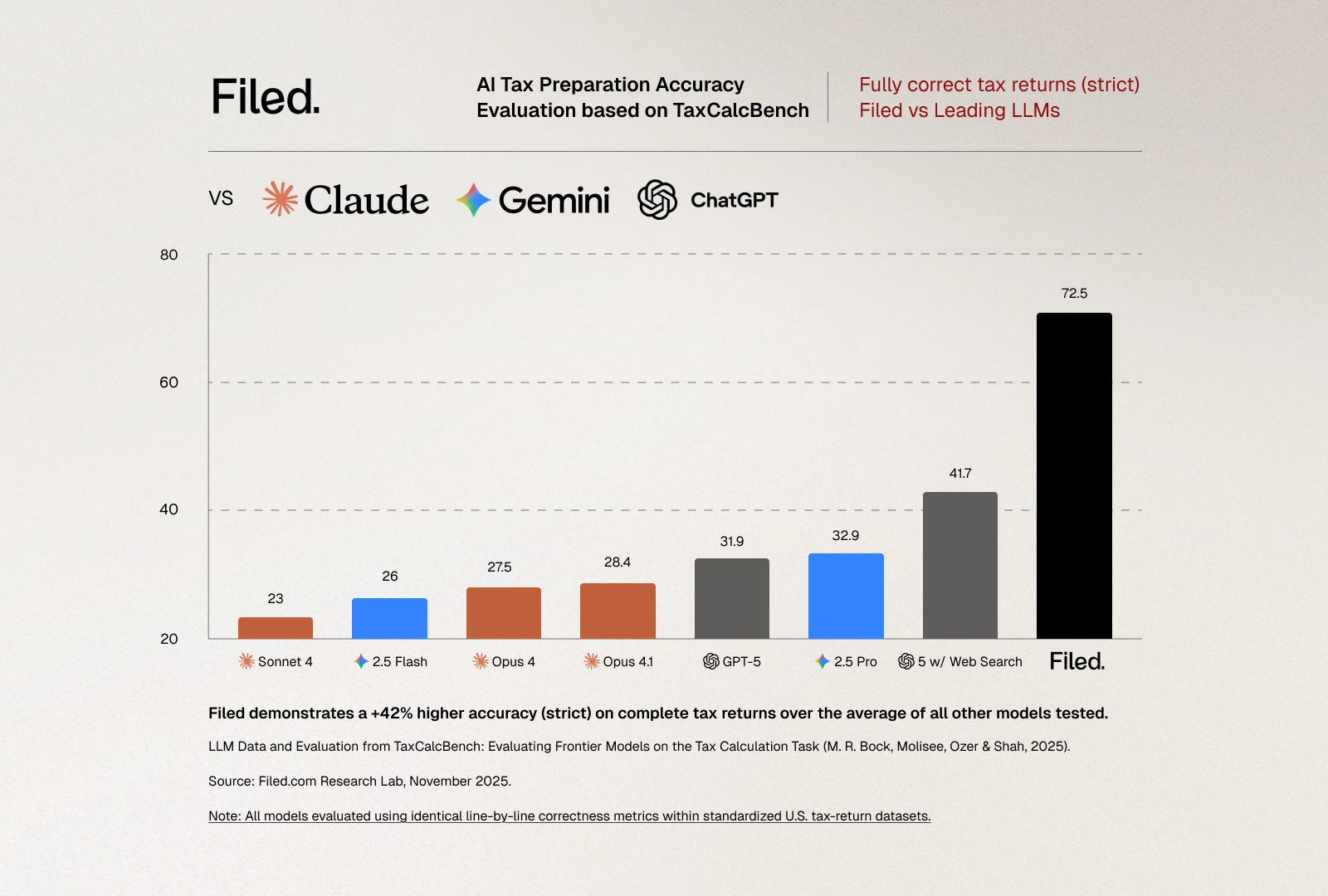
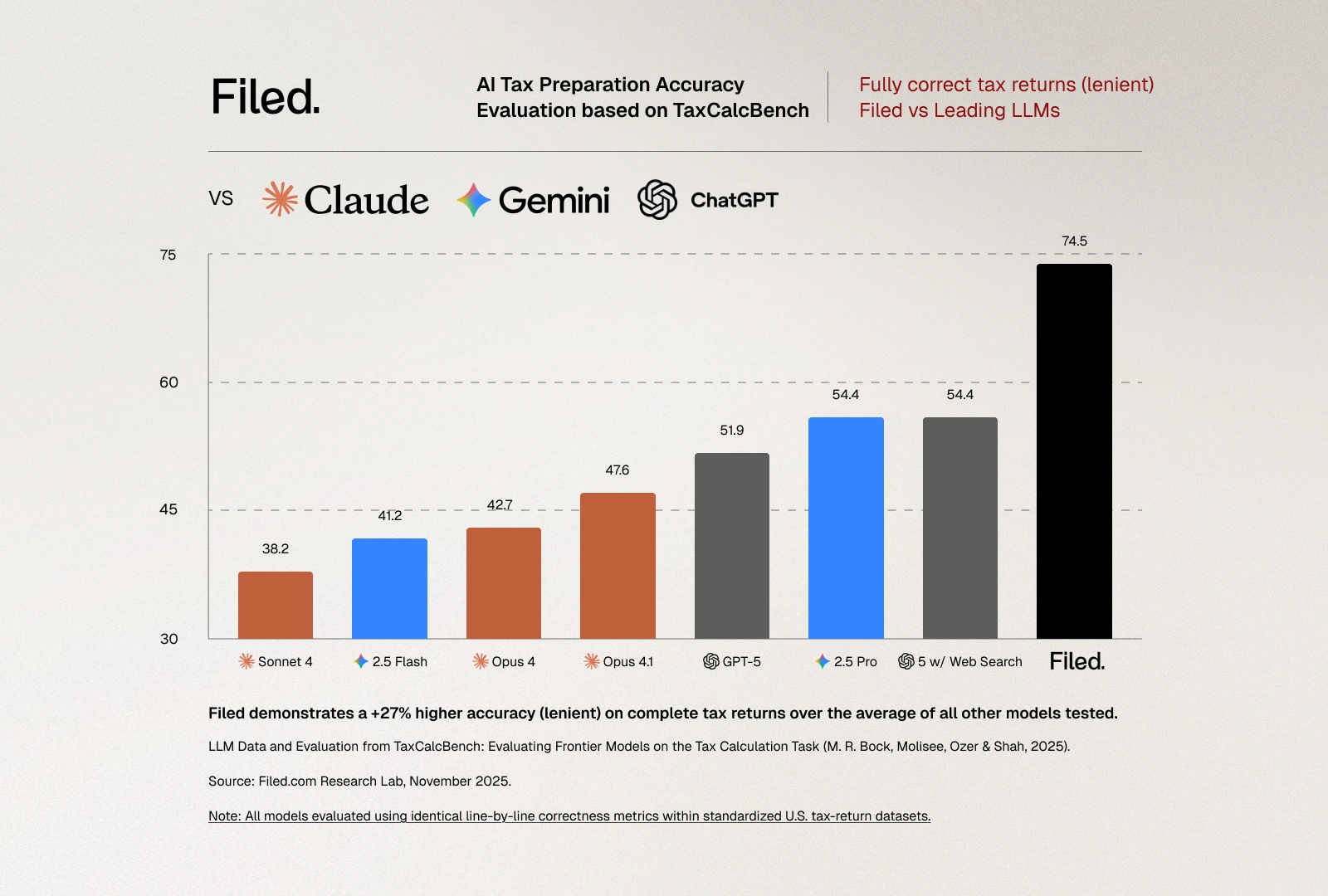
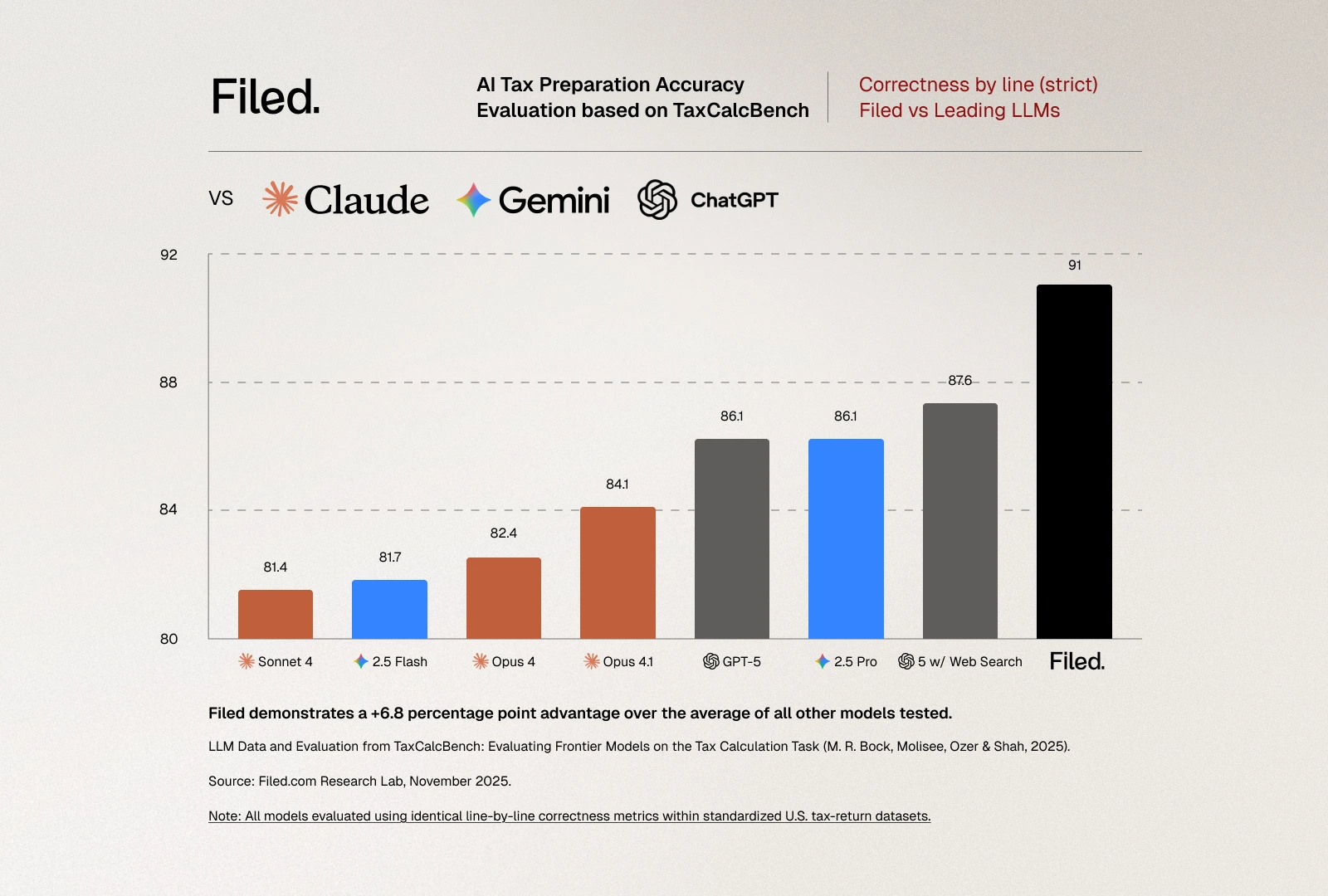
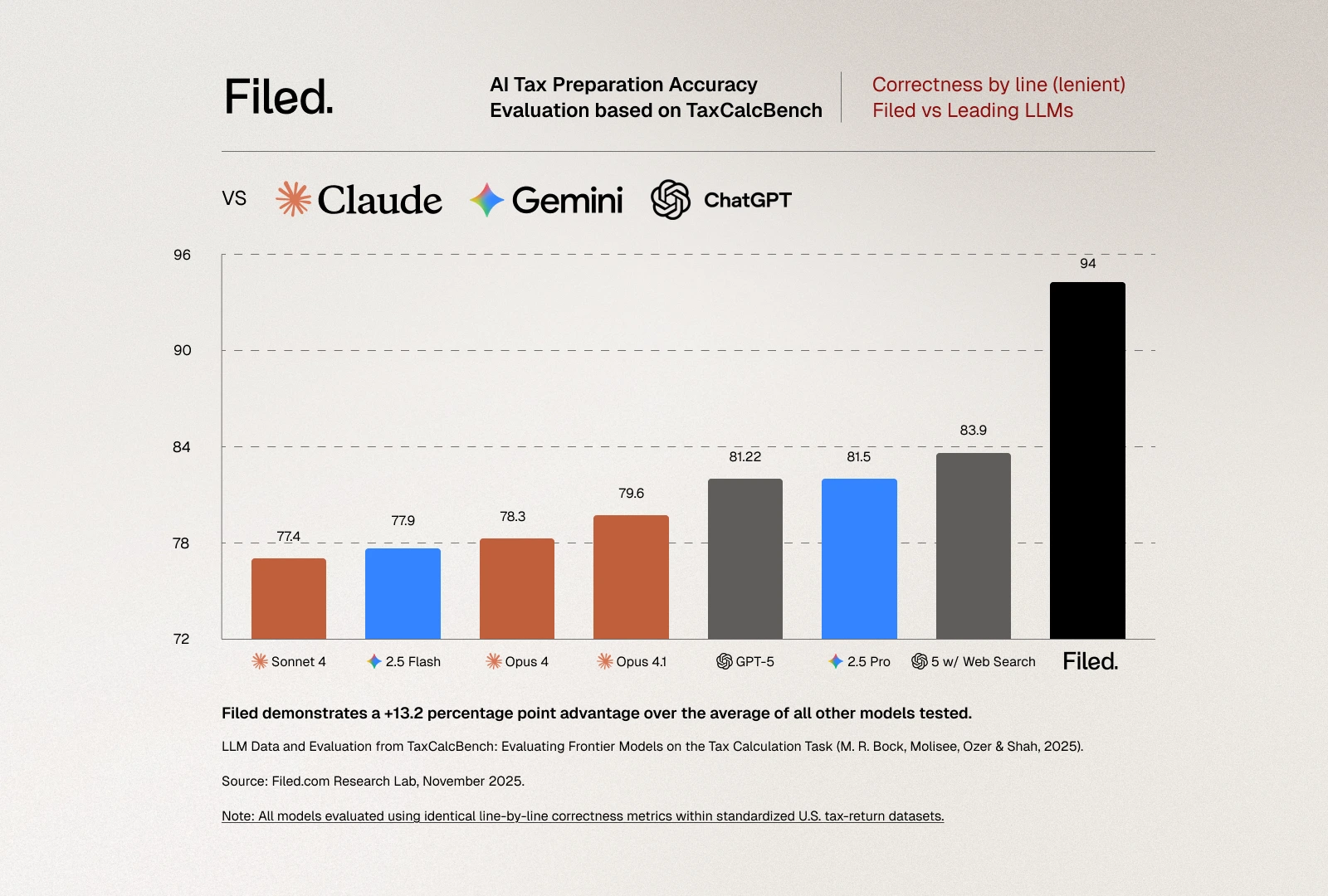
The evaluation criteria are unforgiving, as they should be for tax preparation. A tax return is considered "correct" only if every evaluated field matches the expected value exactly. This strict metric reflects the reality of tax filing: the IRS doesn't accept returns that are "close enough." If Line 16 shows $2,789 in tax owed but the correct amount is $2,792, the return is wrong. Period. There's no partial credit in tax compliance. The benchmark also reports a "lenient" metric allowing for plus-or-minus $5 differences per line, which provides useful diagnostic information about error patterns but has no practical relevance for actual tax filing.
.webp)